Molecular Cartography - QC RNA spots
Florian Wuennemann
Last updated: 2024-03-21
Checks: 7 0
Knit directory: mi_spatialomics/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20230612) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version e6213a5. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rproj.user/
Ignored: analysis/.DS_Store
Ignored: analysis/deprecated/.DS_Store
Ignored: analysis/molecular_cartography_python/.DS_Store
Ignored: analysis/seqIF_python/.DS_Store
Ignored: analysis/seqIF_python/pixie/.DS_Store
Ignored: analysis/seqIF_python/pixie/cell_clustering/
Ignored: annotations/.DS_Store
Ignored: annotations/SeqIF/.DS_Store
Ignored: annotations/molkart/.DS_Store
Ignored: annotations/molkart/Figure1_regions/.DS_Store
Ignored: annotations/molkart/Supplementary_Figure4_regions/.DS_Store
Ignored: data/.DS_Store
Ignored: data/140623.calcagno_et_al.seurat_object.rds
Ignored: data/Calcagno2022_int_logNorm_annot.h5Seurat
Ignored: data/IC_03_IF_CCR2_CD68 cell numbers.xlsx
Ignored: data/Traditional_IF_absolute_cell_counts.csv
Ignored: data/Traditional_IF_relative_cell_counts.csv
Ignored: data/pixie.cell_table_size_normalized_cell_labels.csv
Ignored: data/results_cts_100.sqm
Ignored: data/seqIF_regions_annotations/
Ignored: data/seurat/
Ignored: output/.DS_Store
Ignored: output/mol_cart.harmony_object.h5Seurat
Ignored: output/molkart/
Ignored: output/proteomics/
Ignored: output/results_cts.lowres.125.sqm
Ignored: output/seqIF/
Ignored: pipeline_configs/.DS_Store
Ignored: plots/
Ignored: references/.DS_Store
Ignored: renv/.DS_Store
Ignored: renv/library/
Ignored: renv/staging/
Untracked files:
Untracked: analysis/deprecated/figures.supplementary_figureX.Rmd
Untracked: analysis/deprecated/figures.supplementary_figure_X.MistyR.Rmd
Unstaged changes:
Deleted: analysis/figures.supplementary_figureX.Rmd
Deleted: analysis/figures.supplementary_figure_X.MistyR.Rmd
Deleted: analysis/figures.supplementary_figure_X.proteomics_qc.Rmd
Deleted: figures/Figure_5.eps
Deleted: figures/Figure_5.pdf
Deleted: figures/Figure_5.png
Deleted: figures/Figure_5.svg
Deleted: figures/Supplementary_Figure_1_Molecular_Cartography_ROIs.png
Deleted: figures/Supplementary_figure_5.segmentation_metrics.poster.eps
Modified: figures/Supplementary_figure_X.proteomics.eps
Modified: figures/Supplementary_figure_X.proteomics.png
Deleted: results_cts.lowres.125.sqm
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/molkart.QC_spots.Rmd) and
HTML (docs/molkart.QC_spots.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 56559c7 | FloWuenne | 2024-03-21 | Cleaned up repository. |
| Rmd | f4d5c82 | FloWuenne | 2024-01-15 | Latest update to Seurat analysis with reprocessed data. |
| html | f4d5c82 | FloWuenne | 2024-01-15 | Latest update to Seurat analysis with reprocessed data. |
| Rmd | 5dee03d | FloWuenne | 2023-09-04 | Latest code update. |
| html | 67e546d | FloWuenne | 2023-07-23 | Build site. |
| Rmd | d6085a2 | FloWuenne | 2023-07-23 | Upadte since error for building. |
| html | 5816aca | FloWuenne | 2023-06-12 | Build site. |
| Rmd | 3b5ca40 | FloWuenne | 2023-06-12 | Added code for supplementary Figures. |
| html | 3b5ca40 | FloWuenne | 2023-06-12 | Added code for supplementary Figures. |
Introduction
Here we will use the deduplicated RNA spot tables to calculate the transcript abundances per sample, as well as calculate
Correlation between technical replicates
Read data
## This script will take the Molecular Cartography spot count tables transform them from tsv
data_dir <- "../data/nf-core_molkart/mindagap"
all_samples <- list()
all_files <- list.files(data_dir)
for(this_file in all_files){
if(grepl("txt",this_file)){
print(this_file)
sample_tx <- vroom(paste(data_dir,this_file,sep="/"),col_names = c("x","y","z","gene"),col_select = c(x,y,z,gene))
sample_tx$sample <- this_file
sample_tx_sums <- sample_tx %>%
subset(gene != "Duplicated") %>%
count(gene) %>%
mutate("sample" = this_file) %>%
separate(sample, into = c("x","time","replicate","slide","spots"),
remove = FALSE) %>%
select(-c(x,spots)) %>%
mutate("sample_ID" = paste("sample",time,replicate,sep="_"),
"total_tx" = n) %>%
select(-n) %>%
arrange(desc(total_tx))
all_samples[[this_file]] <- sample_tx_sums
}
}[1] "sample_2d_r1_s1_sample_2d_r1_s1.spots_markedDups.txt"Rows: 940788 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 99 rows [1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_2d_r1_s2_sample_2d_r1_s2.spots_markedDups.txt"Rows: 2242464 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 99 rows [1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_2d_r2_s1_sample_2d_r2_s1.spots_markedDups.txt"Rows: 1055509 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 100 rows [1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_2d_r2_s2_sample_2d_r2_s2.spots_markedDups.txt"Rows: 1855385 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 98 rows [1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_4d_r1_s1_sample_4d_r1_s1.spots_markedDups.txt"Rows: 4988178 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 100 rows [1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_4d_r1_s2_sample_4d_r1_s2.spots_markedDups.txt"Rows: 1225229 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 100 rows [1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_4d_r2_s1_sample_4d_r2_s1.spots_markedDups.txt"Rows: 1231209 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 99 rows [1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_4d_r2_s2_sample_4d_r2_s2.spots_markedDups.txt"Rows: 758844 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 99 rows [1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_4h_r1_s1_sample_4h_r1_s1.spots_markedDups.txt"Rows: 3037103 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 100 rows [1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_4h_r1_s2_sample_4h_r1_s2.spots_markedDups.txt"Rows: 2200936 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 100 rows [1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_4h_r2_s1_sample_4h_r2_s1.spots_markedDups.txt"Rows: 417879 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 98 rows [1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_4h_r2_s2_sample_4h_r2_s2.spots_markedDups.txt"Rows: 2132153 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 98 rows [1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_control_r1_s1_sample_control_r1_s1.spots_markedDups.txt"Rows: 5558060 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 99 rows [1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_control_r1_s2_sample_control_r1_s2.spots_markedDups.txt"Rows: 5188851 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 100 rows [1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_control_r2_s1_sample_control_r2_s1.spots_markedDups.txt"Rows: 4657621 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 100 rows [1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].[1] "sample_control_r2_s2_sample_control_r2_s2.spots_markedDups.txt"Rows: 4854327 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): gene
dbl (3): x, y, z
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning: Expected 5 pieces. Additional pieces discarded in 100 rows [1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, ...].Merge data per biological replicate by slide
all_samples_df <- bind_rows(all_samples, .id = "column_label")
all_samples_df <- all_samples_df %>%
select(total_tx, gene, sample_ID, slide,time)
slide1 <- subset(all_samples_df,slide == "s1") %>% select(-slide)
slide2 <- subset(all_samples_df,slide == "s2") %>% select(-slide)
merge_tx_sums <- full_join(slide1,slide2, by = c("gene","sample_ID","time"), suffix = c("_rep1","_rep2"))Write data for plotting
vroom_write(merge_tx_sums,
file = here("./output/molkart/tx_abundances_per_slide.tsv"))Principal component analysis of spot counts
all_samples_df <- bind_rows(all_samples, .id = "column_label")
all_samples_df <- all_samples_df %>%mutate("sample_ID" = paste("sample",time,replicate,slide,sep="_"))
metadata <- all_samples_df %>%
select(sample_ID,replicate,slide,time)
exp_mat <- all_samples_df %>%
select(sample_ID,total_tx,gene) %>%
pivot_wider(names_from = "gene",
values_from = "total_tx")
samples <- exp_mat$sample_ID
exp_mat <- exp_mat %>% select(-sample_ID)
exp_mat <- as.matrix(exp_mat)
exp_mat[is.na(exp_mat)] <- 0## Perform PCA
library(factoextra)Welcome! Want to learn more? See two factoextra-related books at https://goo.gl/ve3WBares.pca <- prcomp(exp_mat,center = TRUE, scale = TRUE, retx = TRUE)
fviz_eig(res.pca)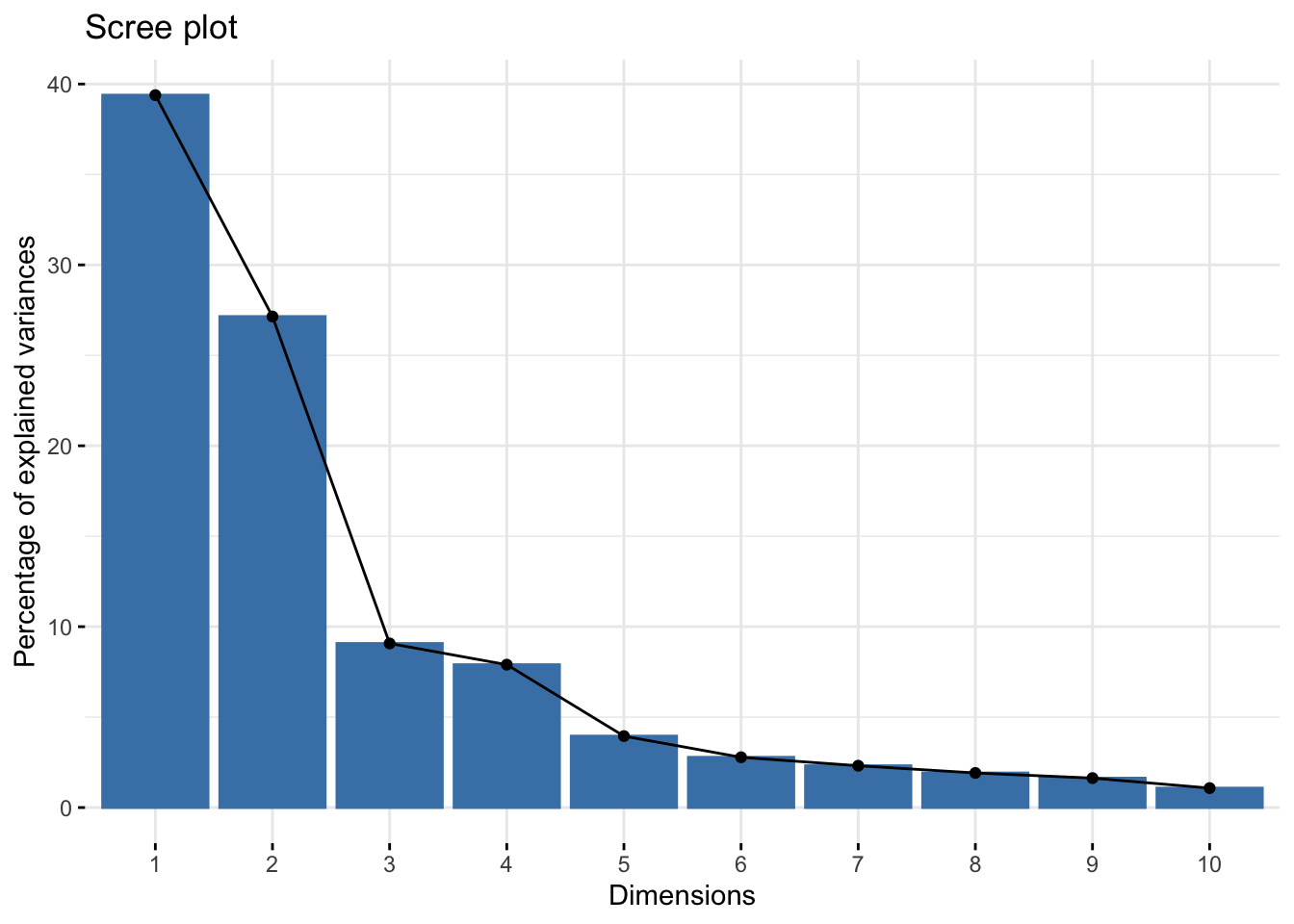
| Version | Author | Date |
|---|---|---|
| 3b5ca40 | FloWuenne | 2023-06-12 |
## Plot PCAs
pcs <- as.data.frame(res.pca$x)
pcs$sample <- samples
pcs <- pcs %>%
mutate("time" = if_else(grepl("control",sample),"control",
if_else(grepl("4h",sample),"4h",
if_else(grepl("2d",sample),"2d","4d")))
)
pcs$time <- factor(pcs$time,levels= c("control","4h","2d","4d"))
pcs$label <- gsub(".spots.txt","",pcs$sample)
pcs <- pcs %>%
separate("sample", into = c("string","time","replicate","slide"))
pcs <- pcs %>%
select(-c(string))
pcs$slide <- gsub("s1","Slide 1",pcs$slide)
pcs$slide <- gsub("s2","Slide 2",pcs$slide)
pcs$time <- factor(pcs$time,
levels = c("control","4h","2d","4d"))
pca_plot <- ggplot(pcs,aes(PC1,PC2,label = label)) +
geom_point(size = 4, aes(color = time, shape = slide)) +
scale_color_brewer(palette = "Dark2",labels = c("control","4 hours","2 days","4 days")) +
labs(color = "Time",
shape = "Slide") +
background_grid()
pca_plot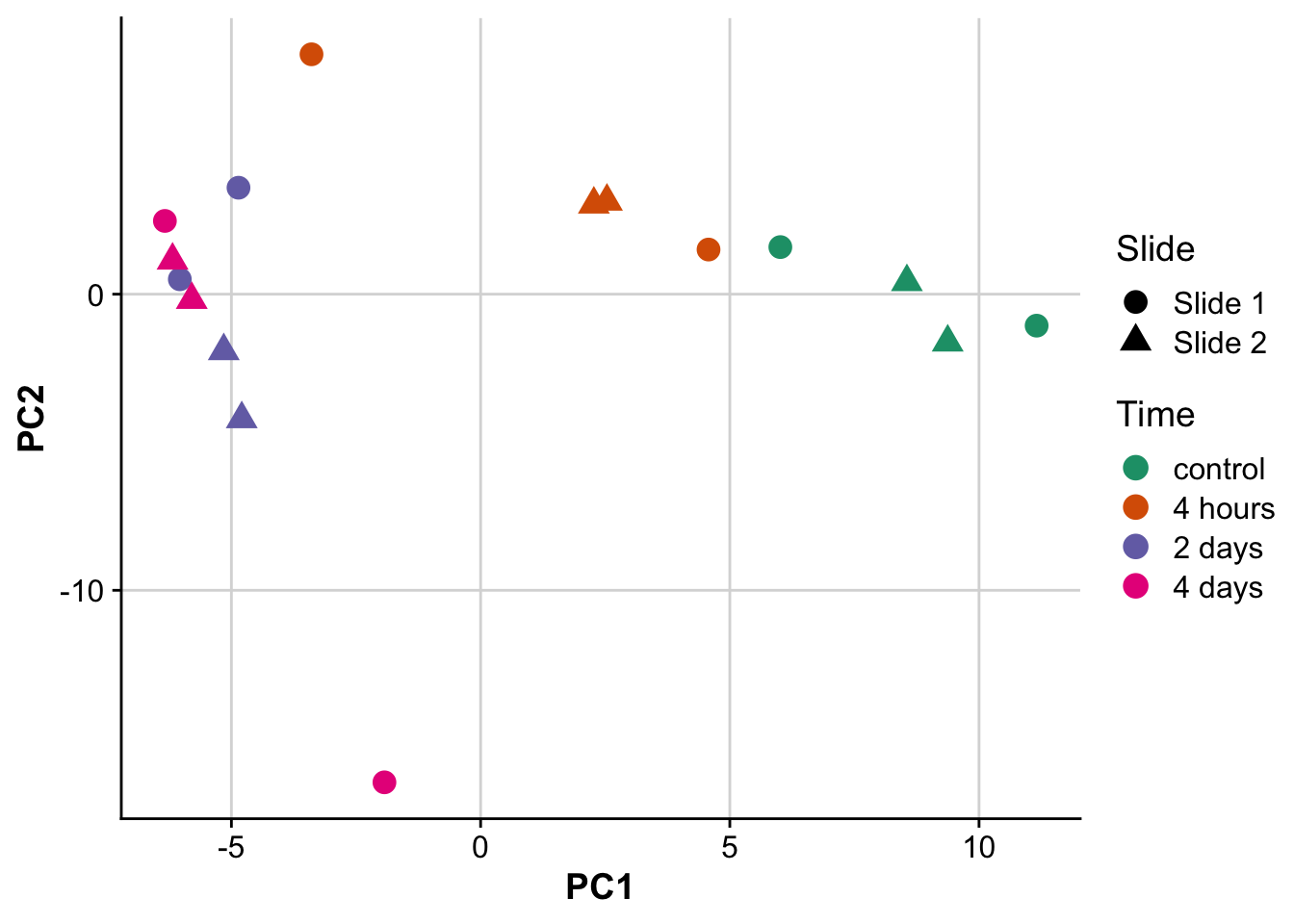
write.table(pcs,
file = "./output/molkart/pca_spots.tsv",
sep = "\t",
col.names = TRUE,
row.names = FALSE,
quote = FALSE)
sessionInfo()R version 4.3.1 (2023-06-16)
Platform: aarch64-apple-darwin20 (64-bit)
Running under: macOS Sonoma 14.1.2
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Europe/Berlin
tzcode source: internal
attached base packages:
[1] stats graphics grDevices datasets utils methods base
other attached packages:
[1] factoextra_1.0.7 RColorBrewer_1.1-3 ggsci_3.0.0 cowplot_1.1.2
[5] ggrepel_0.9.5 patchwork_1.2.0 ggpubr_0.6.0 lubridate_1.9.3
[9] forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4 purrr_1.0.2
[13] readr_2.1.5 tidyr_1.3.0 tibble_3.2.1 ggplot2_3.4.4
[17] tidyverse_2.0.0 vroom_1.6.5 here_1.0.1 workflowr_1.7.1
loaded via a namespace (and not attached):
[1] gtable_0.3.4 xfun_0.41 bslib_0.6.1
[4] rstatix_0.7.2 processx_3.8.3 callr_3.7.3
[7] tzdb_0.4.0 vctrs_0.6.5 tools_4.3.1
[10] ps_1.7.6 generics_0.1.3 parallel_4.3.1
[13] fansi_1.0.6 highr_0.10 pkgconfig_2.0.3
[16] lifecycle_1.0.4 farver_2.1.1 compiler_4.3.1
[19] git2r_0.33.0 munsell_0.5.0 getPass_0.2-4
[22] carData_3.0-5 httpuv_1.6.14 htmltools_0.5.7
[25] sass_0.4.8 yaml_2.3.8 car_3.1-2
[28] later_1.3.2 pillar_1.9.0 crayon_1.5.2
[31] jquerylib_0.1.4 whisker_0.4.1 cachem_1.0.8
[34] abind_1.4-5 tidyselect_1.2.0 digest_0.6.34
[37] stringi_1.8.3 labeling_0.4.3 rprojroot_2.0.4
[40] fastmap_1.1.1 grid_4.3.1 colorspace_2.1-0
[43] cli_3.6.2 magrittr_2.0.3 utf8_1.2.4
[46] broom_1.0.5 withr_2.5.2 backports_1.4.1
[49] scales_1.3.0 promises_1.2.1 bit64_4.0.5
[52] timechange_0.2.0 rmarkdown_2.25 httr_1.4.7
[55] bit_4.0.5 ggsignif_0.6.4 hms_1.1.3
[58] evaluate_0.23 knitr_1.45 rlang_1.1.3
[61] Rcpp_1.0.12 glue_1.7.0 BiocManager_1.30.22
[64] renv_1.0.3 rstudioapi_0.15.0 jsonlite_1.8.8
[67] R6_2.5.1 fs_1.6.3